Create Apache Flink® data service integrations#
With Apache Flink®, you can create streaming data pipelines across services. Aiven for Apache Flink® currently supports Aiven for Apache Kafka®, Aiven for PostgreSQL®, and Aiven for OpenSearch® as sources and targets for Flink applications.
To use Aiven for Apache Kafka, Aiven for PostgreSQL, or Aiven for OpenSearch as a source or target for a Flink application, you will need to integrate the related service with Aiven for Apache Flink.
Create data service integration#
You can easily create Aiven for Apache Flink® data service integrations via the Aiven Console by following these steps:
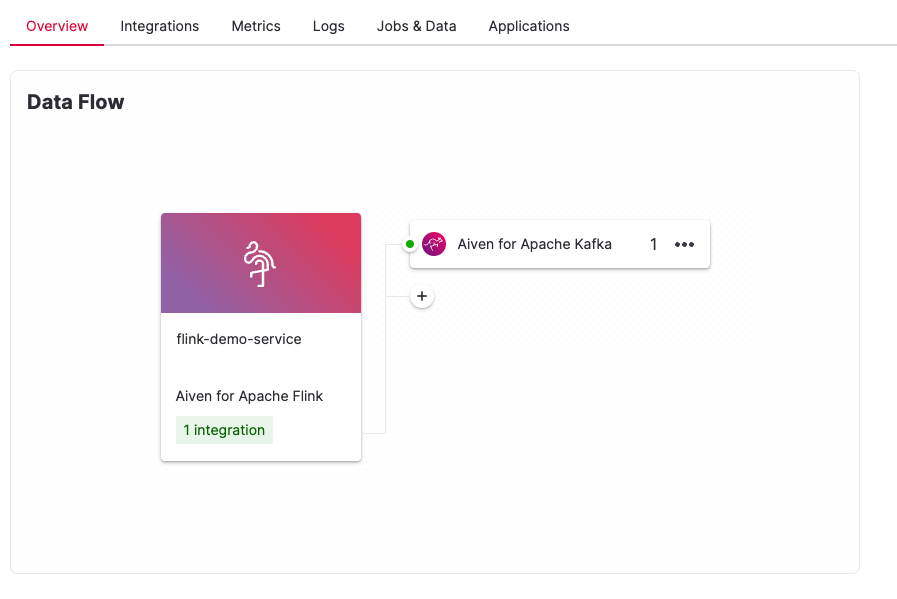
Navigate to the Aiven for Apache Flink® service page.
If you are setting up the first integration for the selected Aiven for Apache Flink service, select Get Started in the service Overview screen.
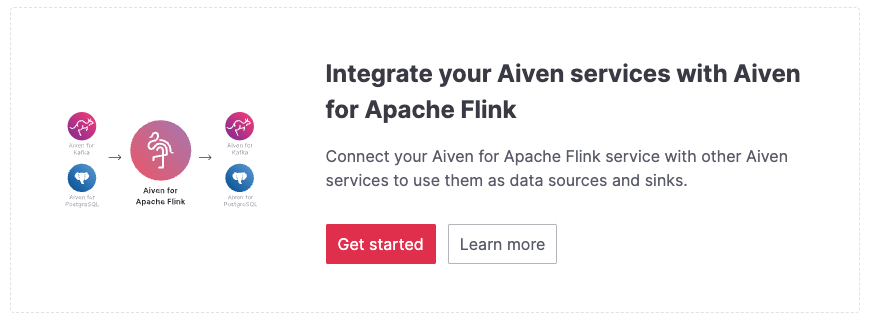
To configure the data flow with Apache Flink®, select the Aiven for Apache Kafka®, Aiven for PostgreSQL®, or Aiven for OpenSearch® service that you wish to integrate. Click the Integrate button to complete the integration process.
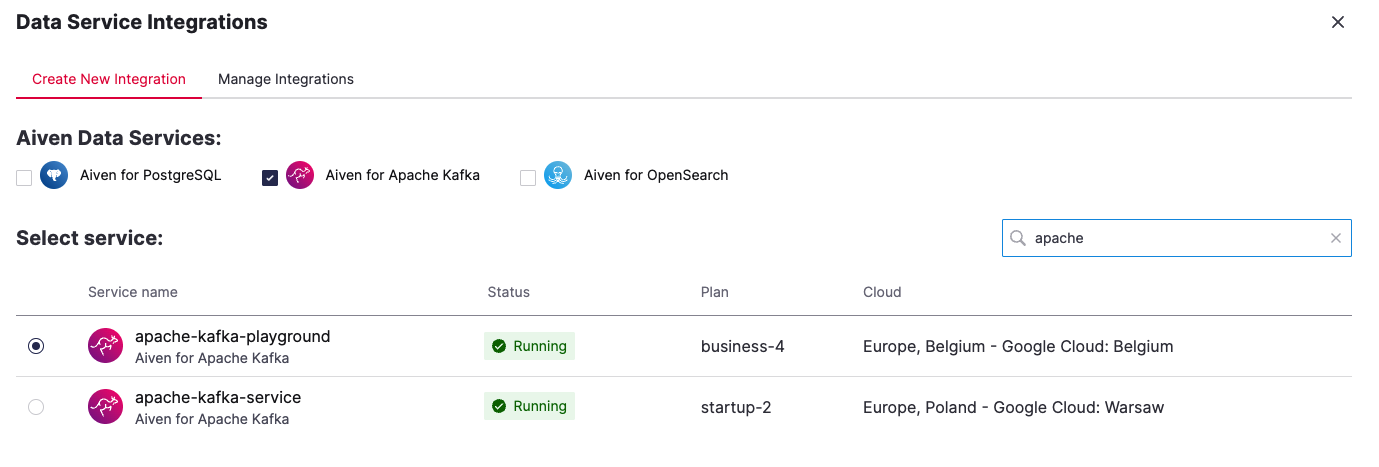
You can include additional integrations using the plus(+) button in the Data Flow section